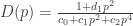![]()
When I was a graduate student I heard a lot about the wonderful performances of a Cray-1 parallel computer and the promises to explore unknown fields of knowledge with this unleashed power. This admirable machine reached a peak of 250 Mflops. Its near parent, Cray-2, performed at 1700 Mflops and for scientists this was indeed a new era in the help to attack difficult mathematical problems.  But when you look at QCD all these seem just toys for a kindergarten and one is not even able to perform the simplest computations to extract meaningful physical results. So, physicists started to project very specialized machines to hope to improve the situation.
But when you look at QCD all these seem just toys for a kindergarten and one is not even able to perform the simplest computations to extract meaningful physical results. So, physicists started to project very specialized machines to hope to improve the situation.
Today the situation is changed dramatically. The reason is that the increasing need for computation to perform complex tasks on a video output requires extended parallel computation capability for very simple mathematical tasks. But these mathematical tasks is all one needs to perform scientific computations. The flagship company in this area is Nvidia that produced CUDA for their graphic cards. This means that today one can have outperforming parallel computation on a desktop computer and we are talking of some Teraflops capability! All this at a very affordable cost. With few bucks you can have on your desktop a machine performing thousand times better than a legendary Cray machine. Now, a counterpart machine of a Cray-1 is a CUDA cluster breaking the barrier of Petaflops! Something people were dreaming of just a few years ago. This means that you can do complex and meaningful QCD computations in your office, when you like, without the need to share CPU time with anybody and pushing your machine at its best. All this with costs that are not a concern anymore.
So, with this opportunity in sight, I jumped on this bandwagon and a few months ago I upgraded my desktop computer at home into a CUDA supercomputer. The first idea was just to buy old material from Ebay at very low cost to build on what already was on my machine. On 2008 the top of the GeForce Nvidia cards was a 9800 GX2. This card comes equipped with a couple of GPUs with 128 cores each one, 0.5 Gbyte of ram for each GPU and support for CUDA architecture 1.1. No double precision available.  This option started to be present with cards having CUDA architecture 1.3 some time later. You can find a card of this on Ebay for about 100-120 euros. You will also need a proper motherboard. Indeed, again on 2008, Nvidia produced nForce 790i Ultra properly fitted for these aims. This card is fitted for a 3-way SLI configuration and as my readers know, I installed till 3 9800 GX2 cards on it. I have got this card on Ebay for a similar pricing as for the video cards. Also, before to start this adventure, I already had a 750 W Cooler Master power supply. It took no much time to have this hardware up and running reaching the considerable computational power of 2 Tflops in single precision, all this with hardware at least 3 years old! For the operating system I chose Windows 7 Ultimate 64 bit after an initial failure with Linux Ubuntu 64 bit.
This option started to be present with cards having CUDA architecture 1.3 some time later. You can find a card of this on Ebay for about 100-120 euros. You will also need a proper motherboard. Indeed, again on 2008, Nvidia produced nForce 790i Ultra properly fitted for these aims. This card is fitted for a 3-way SLI configuration and as my readers know, I installed till 3 9800 GX2 cards on it. I have got this card on Ebay for a similar pricing as for the video cards. Also, before to start this adventure, I already had a 750 W Cooler Master power supply. It took no much time to have this hardware up and running reaching the considerable computational power of 2 Tflops in single precision, all this with hardware at least 3 years old! For the operating system I chose Windows 7 Ultimate 64 bit after an initial failure with Linux Ubuntu 64 bit.
There is a wide choice in the web for software to run for QCD. The most widespread is surely the MILC code. This code is written for a multi-processor environment and represents the effort of several people spanning several years of development. It is well written and rather well documented. From this code a lot of papers on lattice QCD have gone through the most relevant archival journals. Quite recently they started to port this code on CUDA GPUs following a trend common to all academia. Of course, for my aims, being a lone user of CUDA and having no much time for development, I had the no much attractive perspective to try the porting of this code on GPUs. But, in the same time when I upgraded my machine, Pedro Bicudo and Nuno Cardoso published their paper on arxiv (see here) and made promptly available their code for SU(2) QCD on CUDA GPUs. You can download their up-to-date code here (if you plan to use this code just let them know as they are very helpful). So, I ported this code, originally written for Linux, to Windows 7 and I have got it up and running obtaining a right output for a lattice till 
In these days I made another effort to improve my machine. The idea is to improve in performance like larger lattices and shorter execution times while reducing overheating and noise.  Besides, the hardware I worked with was so old that the architecture did not make available double precision. So, I decided to buy a couple of GeForce 580 GTX. This is the top of the GeForce cards (590 GTX is a couple of 580 GTX on a single card) and yields 1.5 Tflops in single precision (9800 GX2 stopped at 1 Tflops in single precision). It has Fermi architecture (CUDA 2.0) and grants double precision at a possible performance of at least 0.5 Tflops. But as happens for all video cards, a model has several producers and these producers may decide to change something in performance. After some difficulties with the dealer, I was able to get a couple of high-performance MSI N580GTX Twin Frozr II/OC at a very convenient price. With respect to Nvidia original card, these come overclocked, with a proprietary cooler system that grants a temperature reduced of 19°C with respect to the original card. Besides, higher quality components were used. I received these cards yesterday and I have immediately installed them. In a few minutes Windows 7 installed the drivers. I recompiled my executable and finally I performed a successful computation to
Besides, the hardware I worked with was so old that the architecture did not make available double precision. So, I decided to buy a couple of GeForce 580 GTX. This is the top of the GeForce cards (590 GTX is a couple of 580 GTX on a single card) and yields 1.5 Tflops in single precision (9800 GX2 stopped at 1 Tflops in single precision). It has Fermi architecture (CUDA 2.0) and grants double precision at a possible performance of at least 0.5 Tflops. But as happens for all video cards, a model has several producers and these producers may decide to change something in performance. After some difficulties with the dealer, I was able to get a couple of high-performance MSI N580GTX Twin Frozr II/OC at a very convenient price. With respect to Nvidia original card, these come overclocked, with a proprietary cooler system that grants a temperature reduced of 19°C with respect to the original card. Besides, higher quality components were used. I received these cards yesterday and I have immediately installed them. In a few minutes Windows 7 installed the drivers. I recompiled my executable and finally I performed a successful computation to 
- CPU Intel E8500
- CPU Cooler Coolermaster Hyper 212
- 8 Gbyte RAM DD3 1333 MHz (Kingston ValueRAM)
- Motherboard nForce 790i Ultra
- 2x MSI N580GTX Twin Frozr II/OC
- PSU Coolermaster Silent Pro Gold 1000 W
- HD Seagate 1.5 TB, WDC Caviar Green 1 TB, Seagate IDE 500 GB, Seagate 250 GB
- DVD-R/RW IDE Teac
So far, I have had no much time to experiment with the new hardware. I hope to say more to you in the near future. Just stay tuned!
Nuno Cardoso, & Pedro Bicudo (2010). SU(2) Lattice Gauge Theory Simulations on Fermi GPUs J.Comput.Phys.230:3998-4010,2011 arXiv: 1010.4834v2



 Posted by mfrasca
Posted by mfrasca