![]()
So far, I believed to be the only man on Earth to trust a complete absence of mass terms in the Standar Model (we call this conformal symmetry). I was wrong. Krzysztof Meissner and Hermann Nicolai anticipated this idea. Indeed, in a model where mass is generally banned, there is no reason to believe that also the field that is the source of mass should keep a mass term (imaginary or real). We have one more reason to believe in such a scenario and it is the hierarchy problem as the quadratic term in the Higgs field just produces that awkward dependence on the square of the cut-off, the reason why people immediately thought that something else must be in that sector of the model. Meissner and Nicolai obtained their paper published on Physics Letters B and can be found here. As they point out in the article, the problem is to get a meaningful mass for the Higgs field, provided one leaves the self-coupling to be small. I do not agree at all with the reasons for this, the Landau pole, as I have already widely said in this blog. One cannot built general results starting from perturbation theory. But assuming that this is indeed the case, the only mechanism at our disposal to get a mass is the Coleman-Weinberg mechanism. In this case, radiative corrections produce an effective potential that has a non-trivial minimum. The problem again is that this is obtained using small perturbation theory and so, the mass one gets is too small to be physically meaningful. The authors circumvent the problem adding a further scalar field. In this case the model appears to be consistent and all is properly working. What I would like to emphasize is that, if one assumes conformal symmetry to hold for the Standard Model, a single Higgs is not enough. So, I like this paper a lot and I will explain the reasons in a moment. I am convinced that these authors are on the right track.
Two days ago these authors come out with another paper (see here). They claim that the second Higgs has been already seen at CDF (Tevatron), at about 325 GeV, while we know there is just a hint (possibly a fluke) from CMS and nothing from ATLAS for that mass. Of course, there is always the possibility that this resonance escaped due to its really small width.
My personal view was already presented here. At that time, I was not aware of the work by Meissner and Nicolai otherwise I would have used it as a support. The only point I would like to question is the effective generation of mass. There is no generally accepted quantum field theory for a large coupling, neglecting for the moment attempts arising from string theory. Before to say that string theory grants a general approach for strongly coupled problems I would like to see it to give a solution to the scalar massless quartic field theory in such a case. This is the workhorse for this kind of problems and both the communities of physicists and mathematicians were just convinced that perturbation theory has only one side. As I showed here, this is not true. One can do perturbation theory also when a perturbation is taken to go to infinity. This means that we do not need a Coleman-Weinberg mechanism in a conformal Standard Model but we can do perturbation theory assuming a finite self-interaction: An asymptotic perturbation series can be also obtained in this case. But the fundamental conclusions one can draw from this analysis are the following:
- The theory must be supersymmetric.
- The theory has a harmonic oscillator spectrum for a free particle given by
, being
an elliptic integral and
an integration constant with the dimension of energy.
Now, let us look at the last point. One can prove that the decays for the higher excited states are increasingly difficult to observe as their decay constants become exponentially smaller with 
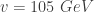
So, what I am saying here is that a conformal Standard Model, not only solves the hierarchy problem, but it is also compelling for the existence of supersymmetry. I think it would be worthy further studies.
Krzysztof A. Meissner, & Hermann Nicolai (2006). Conformal Symmetry and the Standard Model Phys.Lett.B648:312-317,2007 arXiv: hep-th/0612165v4
Krzysztof A. Meissner, & Hermann Nicolai (2012). A 325 GeV scalar resonance seen at CDF? arXiv arXiv: 1208.5653v1
Marco Frasca (2010). Mass generation and supersymmetry arXiv arXiv: 1007.5275v2
Marco Frasca (2010). Glueball spectrum and hadronic processes in low-energy QCD Nucl.Phys.Proc.Suppl.207-208:196-199,2010 arXiv: 1007.4479v2



 Posted by mfrasca
Posted by mfrasca 




